DevOps vs. DataOps : The Process Difference Explained
DataOps: A new revolutionary trend to come in 2019
A great number of disruptive technology trends have appeared on the business horizon in recent years, and it is still counting in 2019. In fact, today’s popularity of DataOps being integrated into the corporate discourse speaks for itself. Just have a look at this zigzag graph with a frequency rate of the term’s usage, presented by Google Trends for 2019.
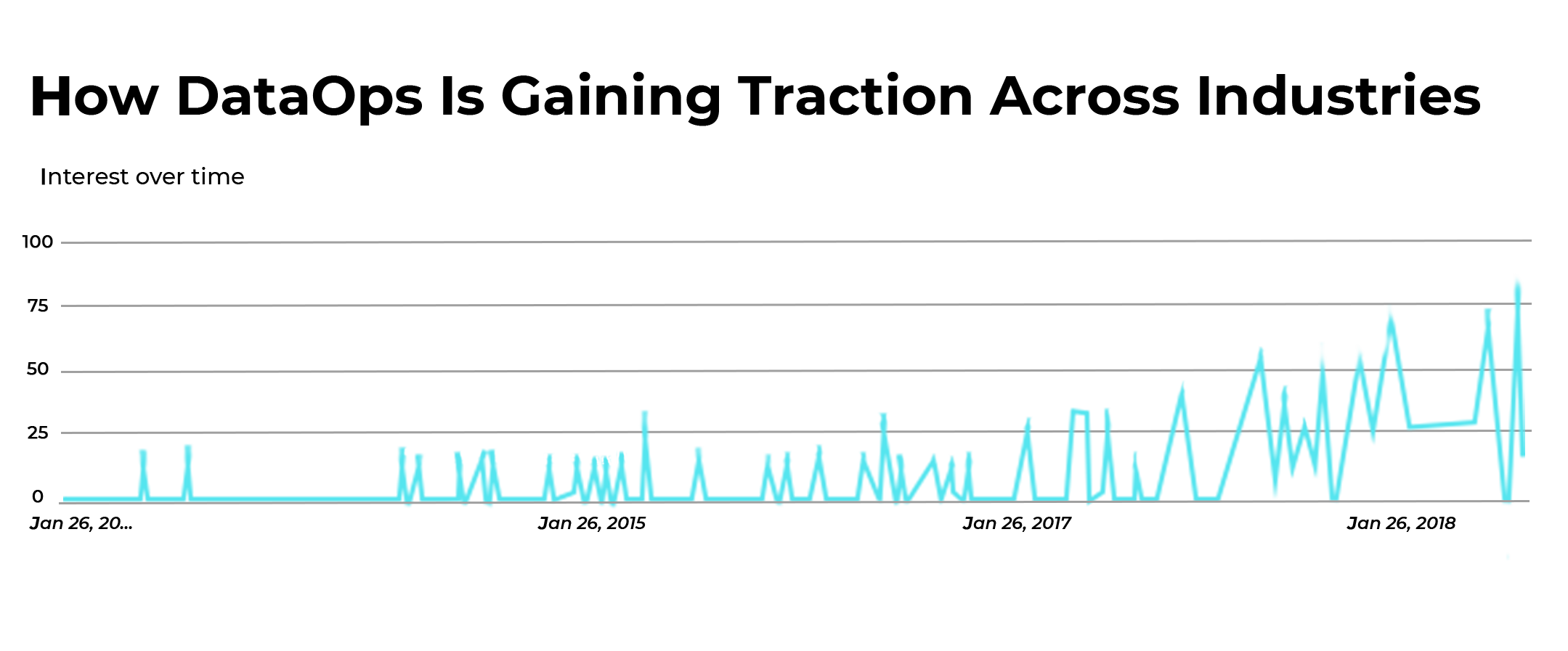
For the uninitiated, however, it may get way too confusing to tell the difference between a plethora of unfamiliar terms and concepts. Here, in this article, we’ll try to help you out with two most notable tech-enabled initiatives that can drastically impact your business growth and profitability.
DevOps: A perfect starting point for DataOps
DevOps as a software development approach is not quite new to business owners. Basically, DevOps is a synergy of both developers and IT operations specialists aimed at reducing costs and time required for software deployment and release cycle. It helps achieve robust collaboration between the back- and front-office teams, which in turn, enables continuous integration and delivery by utilizing automated and iterative processes in their workflow.
DevOps usually employs Agile-based techniques like Scrum, giving much value to the workflow and software deployment optimization. In a word, they provide effective solutions for developers, testers, designers, engineers and other experts that ensure a quick adaptation and delivery cycle, and a much shorter feedback loop.
Using DevOps practices is the best bet when it comes to working in ever-changing environments, where scalability and on-the-go improvements are an issue. What’s more, the DevOps methodology can speed up the migration of all your on-premise software capacities to the cloud-based platforms. With all that said, this approach has become an indispensable part of every company’s strategy.
However, in 2019 businesses face a slew of new challenges that emerge and grow exponentially. So do the enterprise-scale datasets, which need to be dealt with and analyzed properly. In this case, utilizing only DevOps-backed practices seems not to be enough. That’s exactly where DataOps jumps into play providing companies with smooth actionable solutions to streamline their big data acquisition strategy.
How to capitalize on the DataOps innovations?
However, finding the best solution for managing unstructured data-intensive environments is not a cakewalk for businesses in this competitive world. As Forbes indicates, 84% of companies failed to implement digital transformation strategies as of 2016. Unfortunately, the problem is still here in 2019 as most companies lack digitally proficient in-house specialists.
The reason is pure and simple – poor awareness of business owners and their teams on how to integrate new advantageous technologies within their enterprise workflow, especially when it comes to big data acquisition.
“One of the most basic impediment to moving forward on the road to digital transformation is whether or not enough people within the organization are aware of the challenges. The other issue actually, is understanding the drivers of digital transformation so that organizations know where to focus their time and resources.” Michael Gale, a co-author of The Wall Street Journal bestseller, The Digital Helix
Since then, however, many organizations began to try their hand at adopting emerging data-led solutions. Their digital readiness is shown below and it seems the figures look quite optimistic. At least, businesses start realizing that they are badly in need of meaningful solutions to orchestrate massive arrays of data.

As the problem of handling large-scale volumes of enterprise data arises, businesses are striving to adopt the best practices of DevOps and dovetail them with cutting-edge technologies like Artificial Intelligence, Machine Learning and Deep Learning. In view of this, DataOps is a pitch-perfect option for organizations to leverage tried-and-true techniques for the new challenges that come.
This makes DataOps a logical successor of the DevOps initiatives, meaning it taps into all the Agile-led benefits while pairing them deftly with Data Science and Data Engineering assets. The first-movers of this methodology has been already enjoying its competitive advantage within their organizations as the five main benefits of DataOps are really undeniable.
With all that said, the definition of DataOps boils down to the following:
DataOps is a robust tech-driven collaboration of varied professionals and processes to ensure fast, secure and automated data management and curation. Its priority is to increase business revenues and enhance operational efficiencies.
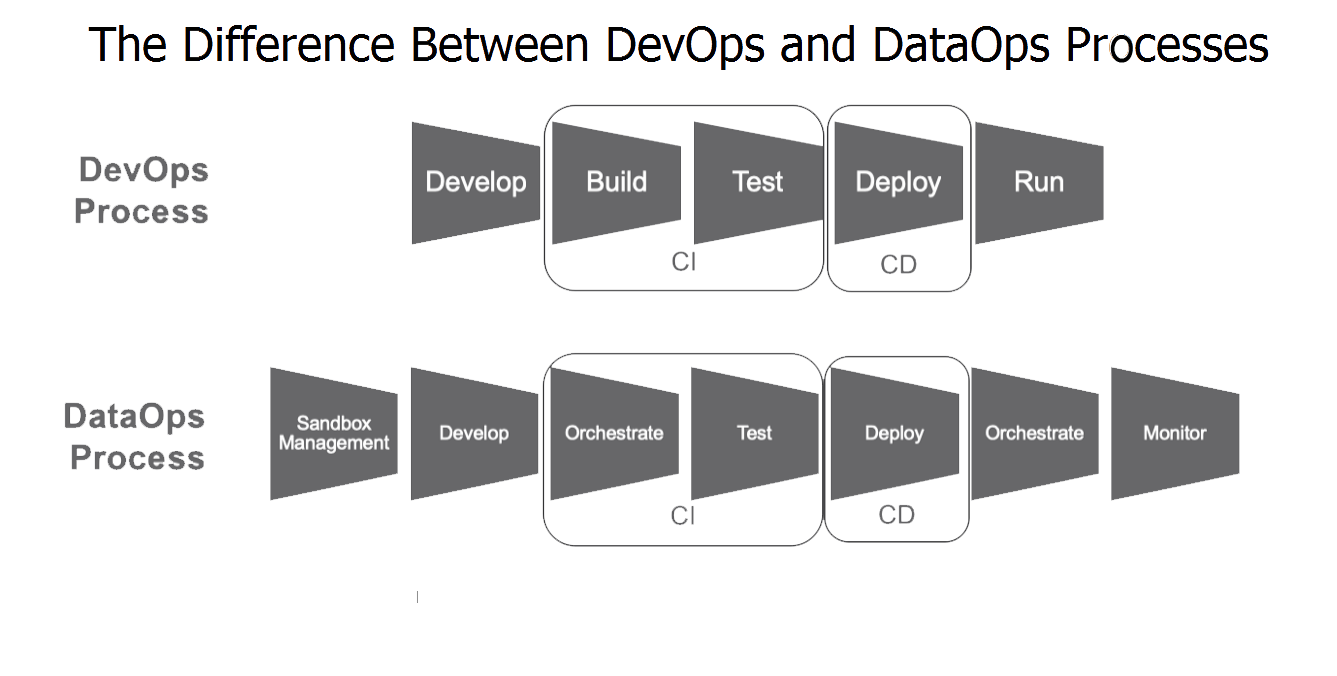
The difference between DevOps and DataOps processes
As it was mentioned above, DataOps utilizes the most effective practices of the Development Operations approach, while being at the same time much more than just a DevOps for data management. The processes involved are way more sophisticated and complex, to say nothing of the ultimate goals to be achieved.

Unlike traditional data management principles, Data Operations as an Agile-driven collaboration of cross-functional software professionals, processes and tech-empowered capabilities makes itself into an actionable holistic operational unity. The responsibilities of all development lifecycle participants and contributors are distributed in alignment with their core competencies within a consolidated iterative workflow.
Although being an integral whole, DataOps can be broken down into a number of activities according to the different teams engaged, just for the sake of convenience.
- Data engineers are responsible for data collection and curation. These data sets are further utilized for evaluating ML algorithms and training Data Science models.
- Data scientists are the best at using programming languages like SAS, R or SQL as well as AI-backed frameworks like TensorFlow, Theano, Keras to develop seamless ML and Deep Learning models.
- Architects and software developers make use of the models generated by data scientists to create full-fledged applications.
- Chief data officers (CDOs) are in charge of IT security and data governance. They provide full or partial access to the pools of historical data for data scientists, in regard to the tasks they need to accomplish.
- The DevOps specialists come into action to support the entire software development lifecycle. They hold responsibility for the automation of processes, application deployment, testing and eventual production releases.
All in all, these two methodologies comprise quite divergent sets of processes, however, some stages may look identical to some extent. As it is shown below, both of them employ the Agile-fueled Continuous Integration (CI) as well as Continuous Deployment (CD) practices across their development pipeline stages. At the same time, DataOps encompasses a much more elaborated scenario, which also considers data-related factors like siloed business data orchestration, data management, monitoring of software deliverables, and more.
Should you be interested in getting the most advantageous DataOps solutions integrated into your business workflow, feel free to contact us. Our experts are always ready to lend a helping hand to those, who want to skyrocket their business revenues, and improve the efficiency of operational workflow and data management.